|
|
|
 View source on GitHub View source on GitHub
|
|
Overview
This notebook will demonstrate how to use the Weight Normalization layer and how it can improve convergence.
WeightNormalization
A Simple Reparameterization to Accelerate Training of Deep Neural Networks:
Tim Salimans, Diederik P. Kingma (2016)
By reparameterizing the weights in this way you improve the conditioning of the optimization problem and speed up convergence of stochastic gradient descent. Our reparameterization is inspired by batch normalization but does not introduce any dependencies between the examples in a minibatch. This means that our method can also be applied successfully to recurrent models such as LSTMs and to noise-sensitive applications such as deep reinforcement learning or generative models, for which batch normalization is less well suited. Although our method is much simpler, it still provides much of the speed-up of full batch normalization. In addition, the computational overhead of our method is lower, permitting more optimization steps to be taken in the same amount of time.
Setup
pip install -U tensorflow-addonsimport tensorflow as tf
import tensorflow_addons as tfa
import numpy as np
from matplotlib import pyplot as plt
# Hyper Parameters
batch_size = 32
epochs = 10
num_classes=10
Build Models
# Standard ConvNet
reg_model = tf.keras.Sequential([
tf.keras.layers.Conv2D(6, 5, activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(16, 5, activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(120, activation='relu'),
tf.keras.layers.Dense(84, activation='relu'),
tf.keras.layers.Dense(num_classes, activation='softmax'),
])
# WeightNorm ConvNet
wn_model = tf.keras.Sequential([
tfa.layers.WeightNormalization(tf.keras.layers.Conv2D(6, 5, activation='relu')),
tf.keras.layers.MaxPooling2D(2, 2),
tfa.layers.WeightNormalization(tf.keras.layers.Conv2D(16, 5, activation='relu')),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tfa.layers.WeightNormalization(tf.keras.layers.Dense(120, activation='relu')),
tfa.layers.WeightNormalization(tf.keras.layers.Dense(84, activation='relu')),
tfa.layers.WeightNormalization(tf.keras.layers.Dense(num_classes, activation='softmax')),
])
Load Data
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
# Convert class vectors to binary class matrices.
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 170498071/170498071 [==============================] - 2s 0us/step
Train Models
reg_model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
reg_history = reg_model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
shuffle=True)
Epoch 1/10 1563/1563 [==============================] - 7s 4ms/step - loss: 1.6086 - accuracy: 0.4134 - val_loss: 1.3833 - val_accuracy: 0.4965 Epoch 2/10 1563/1563 [==============================] - 5s 3ms/step - loss: 1.3170 - accuracy: 0.5296 - val_loss: 1.2546 - val_accuracy: 0.5553 Epoch 3/10 1563/1563 [==============================] - 5s 3ms/step - loss: 1.1944 - accuracy: 0.5776 - val_loss: 1.1566 - val_accuracy: 0.5922 Epoch 4/10 1563/1563 [==============================] - 5s 3ms/step - loss: 1.1192 - accuracy: 0.6033 - val_loss: 1.1554 - val_accuracy: 0.5877 Epoch 5/10 1563/1563 [==============================] - 5s 3ms/step - loss: 1.0576 - accuracy: 0.6243 - val_loss: 1.1264 - val_accuracy: 0.6028 Epoch 6/10 1563/1563 [==============================] - 5s 3ms/step - loss: 1.0041 - accuracy: 0.6441 - val_loss: 1.1555 - val_accuracy: 0.5989 Epoch 7/10 1563/1563 [==============================] - 5s 3ms/step - loss: 0.9626 - accuracy: 0.6605 - val_loss: 1.1076 - val_accuracy: 0.6145 Epoch 8/10 1563/1563 [==============================] - 5s 3ms/step - loss: 0.9207 - accuracy: 0.6734 - val_loss: 1.1362 - val_accuracy: 0.6128 Epoch 9/10 1563/1563 [==============================] - 5s 3ms/step - loss: 0.8836 - accuracy: 0.6872 - val_loss: 1.1191 - val_accuracy: 0.6216 Epoch 10/10 1563/1563 [==============================] - 5s 3ms/step - loss: 0.8559 - accuracy: 0.6963 - val_loss: 1.0973 - val_accuracy: 0.6239
wn_model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
wn_history = wn_model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
shuffle=True)
Epoch 1/10 1563/1563 [==============================] - 10s 5ms/step - loss: 1.6049 - accuracy: 0.4162 - val_loss: 1.3947 - val_accuracy: 0.4967 Epoch 2/10 1563/1563 [==============================] - 8s 5ms/step - loss: 1.3372 - accuracy: 0.5218 - val_loss: 1.2908 - val_accuracy: 0.5305 Epoch 3/10 1563/1563 [==============================] - 8s 5ms/step - loss: 1.2231 - accuracy: 0.5647 - val_loss: 1.2343 - val_accuracy: 0.5590 Epoch 4/10 1563/1563 [==============================] - 8s 5ms/step - loss: 1.1362 - accuracy: 0.5980 - val_loss: 1.1979 - val_accuracy: 0.5782 Epoch 5/10 1563/1563 [==============================] - 7s 5ms/step - loss: 1.0799 - accuracy: 0.6159 - val_loss: 1.1784 - val_accuracy: 0.5860 Epoch 6/10 1563/1563 [==============================] - 8s 5ms/step - loss: 1.0261 - accuracy: 0.6360 - val_loss: 1.1850 - val_accuracy: 0.5818 Epoch 7/10 1563/1563 [==============================] - 8s 5ms/step - loss: 0.9798 - accuracy: 0.6538 - val_loss: 1.1201 - val_accuracy: 0.6082 Epoch 8/10 1563/1563 [==============================] - 8s 5ms/step - loss: 0.9349 - accuracy: 0.6701 - val_loss: 1.1204 - val_accuracy: 0.6136 Epoch 9/10 1563/1563 [==============================] - 8s 5ms/step - loss: 0.8955 - accuracy: 0.6829 - val_loss: 1.1292 - val_accuracy: 0.6103 Epoch 10/10 1563/1563 [==============================] - 8s 5ms/step - loss: 0.8555 - accuracy: 0.6995 - val_loss: 1.1445 - val_accuracy: 0.6103
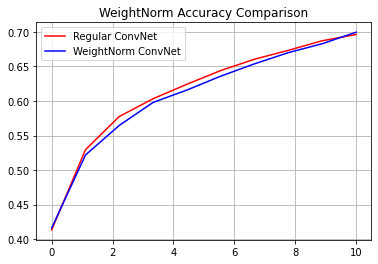
reg_accuracy = reg_history.history['accuracy']
wn_accuracy = wn_history.history['accuracy']
plt.plot(np.linspace(0, epochs, epochs), reg_accuracy,
color='red', label='Regular ConvNet')
plt.plot(np.linspace(0, epochs, epochs), wn_accuracy,
color='blue', label='WeightNorm ConvNet')
plt.title('WeightNorm Accuracy Comparison')
plt.legend()
plt.grid(True)
plt.show()