
نمای کلی
تجزیه و تحلیل مدل TensorFlow (TFMA) کتابخانه ای برای انجام ارزیابی مدل است.
- برای : مهندسان یادگیری ماشین یا دانشمندان داده
- چه کسی : می خواهد مدل های TensorFlow خود را تحلیل و درک کند
- این است : یک کتابخانه مستقل یا جزء یک خط لوله TFX
- که : مدل ها را بر روی مقادیر زیادی از داده ها به صورت توزیع شده بر اساس معیارهای مشابه تعریف شده در آموزش ارزیابی می کند. این معیارها با تکههایی از دادهها مقایسه میشوند و در نوتبوکهای Jupyter یا Colab نمایش داده میشوند.
- بر خلاف : برخی از ابزارهای درون نگری مدل مانند تانسوربرد که درون نگری مدل را ارائه می دهند
TFMA محاسبات خود را با استفاده از پرتو Apache به صورت توزیع شده بر روی مقادیر زیادی داده انجام می دهد. بخشهای زیر نحوه راهاندازی خط لوله ارزیابی اولیه TFMA را شرح میدهند. جزئیات بیشتر معماری را در مورد پیاده سازی اساسی ببینید.
اگر فقط می خواهید وارد شوید و شروع کنید، دفترچه یادداشت colab ما را بررسی کنید.
این صفحه را می توان از tensorflow.org نیز مشاهده کرد.
انواع مدل های پشتیبانی شده
TFMA برای پشتیبانی از مدل های مبتنی بر تنسورفلو طراحی شده است، اما می تواند به راحتی برای پشتیبانی از سایر چارچوب ها نیز گسترش یابد. از لحاظ تاریخی، TFMA نیاز به ایجاد EvalSavedModel برای استفاده از TFMA داشت، اما آخرین نسخه TFMA از چندین نوع مدل بسته به نیاز کاربر پشتیبانی میکند. راه اندازی EvalSavedModel تنها در صورتی باید مورد نیاز باشد که از مدل مبتنی بر tf.estimator استفاده شود و معیارهای زمان آموزش سفارشی مورد نیاز باشد.
توجه داشته باشید که از آنجایی که TFMA اکنون بر اساس مدل سرویس اجرا می شود، TFMA دیگر معیارهای اضافه شده در زمان آموزش را به طور خودکار ارزیابی نمی کند. استثنا در این مورد این است که از یک مدل keras استفاده شود زیرا keras معیارهای استفاده شده در کنار مدل ذخیره شده را ذخیره می کند. با این حال، اگر این یک نیاز سخت است، آخرین TFMA با عقبنشینی سازگار است به طوری که یک EvalSavedModel همچنان میتواند در خط لوله TFMA اجرا شود.
جدول زیر مدل های پشتیبانی شده به طور پیش فرض را خلاصه می کند:
| نوع مدل | معیارهای زمان آموزش | معیارهای پس از آموزش |
|---|---|---|
| TF2 (keras) | Y* | Y |
| TF2 (عمومی) | N/A | Y |
| EvalSavedModel (برآورنده) | Y | Y |
| هیچ (pd.DataFrame و غیره) | N/A | Y |
- معیارهای زمان آموزش به معیارهایی اشاره دارد که در زمان آموزش تعریف شده و با مدل ذخیره شده اند (یا مدل TFMA EvalSavedModel یا مدل ذخیره شده keras). معیارهای پس از آموزش به معیارهای اضافه شده از طریق
tfma.MetricConfigاشاره دارد. - مدلهای عمومی TF2 مدلهای سفارشی هستند که امضاهایی را صادر میکنند که میتوانند برای استنتاج استفاده شوند و بر اساس کراس یا برآوردگر نیستند.
برای اطلاعات بیشتر در مورد نحوه راه اندازی و پیکربندی این انواع مدل های مختلف، به پرسش های متداول مراجعه کنید.
راه اندازی
قبل از اجرای ارزیابی، مقدار کمی تنظیمات لازم است. ابتدا، یک شی tfma.EvalConfig باید تعریف شود که مشخصات مدل، معیارها و برش هایی را که قرار است ارزیابی شوند ارائه کند. دوم باید یک tfma.EvalSharedModel ایجاد شود که به مدل (یا مدلهای) واقعی در طول ارزیابی استفاده شود. هنگامی که اینها تعریف شدند، ارزیابی با فراخوانی tfma.run_model_analysis با مجموعه داده مناسب انجام می شود. برای جزئیات بیشتر، راهنمای نصب را ببینید.
اگر در یک خط لوله TFX اجرا می شود، راهنمای TFX را برای نحوه پیکربندی TFMA برای اجرا به عنوان یک جزء ارزیاب TFX ببینید.
نمونه ها
ارزیابی مدل واحد
موارد زیر از tfma.run_model_analysis برای انجام ارزیابی بر روی یک مدل خدمت استفاده می کند. برای توضیح تنظیمات مختلف مورد نیاز به راهنمای نصب مراجعه کنید.
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path='/path/for/output')
tfma.view.render_slicing_metrics(eval_result)
برای ارزیابی توزیع شده، یک خط لوله پرتو آپاچی با استفاده از یک دونده توزیع شده بسازید. در خط لوله، از tfma.ExtractEvaluateAndWriteResults برای ارزیابی و نوشتن نتایج استفاده کنید. نتایج را می توان برای تجسم با استفاده از tfma.load_eval_result بارگذاری کرد.
به عنوان مثال:
# To run the pipeline.
from google.protobuf import text_format
from tfx_bsl.tfxio import tf_example_record
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
output_path = '/path/for/output'
tfx_io = tf_example_record.TFExampleRecord(
file_pattern=data_location, raw_record_column_name=tfma.ARROW_INPUT_COLUMN)
with beam.Pipeline(runner=...) as p:
_ = (p
# You can change the source as appropriate, e.g. read from BigQuery.
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format. If using EvalSavedModel then use the following
# instead: 'ReadData' >> beam.io.ReadFromTFRecord(file_pattern=...)
| 'ReadData' >> tfx_io.BeamSource()
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
output_path=output_path))
# To load and visualize results.
# Note that this code should be run in a Jupyter Notebook.
result = tfma.load_eval_result(output_path)
tfma.view.render_slicing_metrics(result)
اعتبار سنجی مدل
برای انجام اعتبارسنجی مدل در مقابل یک نامزد و پایه، پیکربندی را بهروزرسانی کنید تا یک تنظیم آستانه را در بر بگیرد و دو مدل را به tfma.run_model_analysis ارسال کنید.
به عنوان مثال:
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics {
class_name: "AUC"
threshold {
value_threshold {
lower_bound { value: 0.9 }
}
change_threshold {
direction: HIGHER_IS_BETTER
absolute { value: -1e-10 }
}
}
}
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_models = [
tfma.default_eval_shared_model(
model_name=tfma.CANDIDATE_KEY,
eval_saved_model_path='/path/to/saved/candiate/model',
eval_config=eval_config),
tfma.default_eval_shared_model(
model_name=tfma.BASELINE_KEY,
eval_saved_model_path='/path/to/saved/baseline/model',
eval_config=eval_config),
]
output_path = '/path/for/output'
eval_result = tfma.run_model_analysis(
eval_shared_models,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path=output_path)
tfma.view.render_slicing_metrics(eval_result)
tfma.load_validation_result(output_path)
تجسم
نتایج ارزیابی TFMA را می توان در یک نوت بوک Jupyter با استفاده از اجزای جلویی موجود در TFMA تجسم کرد. به عنوان مثال:
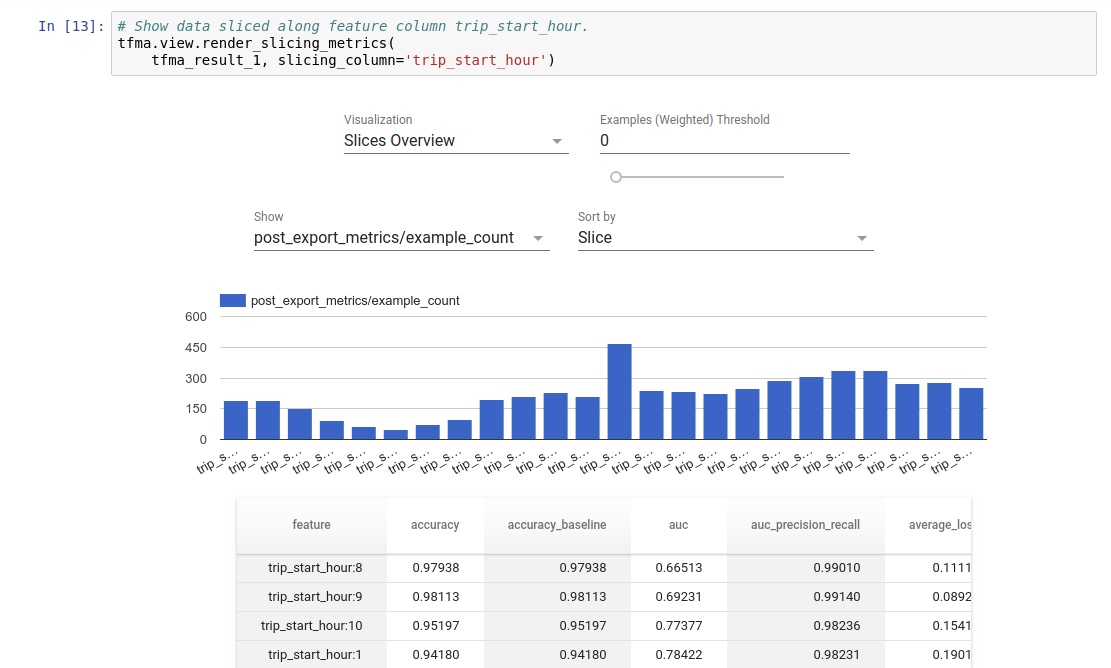 .
.